Mutote, Michael, 22202956
Gattousi, Fadi, 22211572
Diamond Price Prediction Project
Recommendation Systems Project 2 https://mygit.th-deg.de/mm13956/ws-23-sas-02
Task Distribution
| Task | Assigned to |
|---|---|
| GUI | Michael Mutote |
| Plot Functionality | Michael Mutote |
| Data Preprocessing, Analysis and Model Training | Fadi Gattousi |
| General Python Programming | Both |
| Documentation and Readme.md | Fadi Gattousi |
Project Overview
This project aims to predict diamond prices using four different regression models available in scikit-learn. It includes a Python script (Main.py) with a graphical user interface (GUI) for visualizing and interacting with the data and predictions. The dataset (diamonds.csv) consists of various attributes of diamonds. A Jupyter notebook (training.ipynb) is provided for data preprocessing, model training, and evaluation.
Setup and Installation
To set up this project, you need to install the required Python packages. You can do this by running the following command in your terminal:
pip install -r requirements.txtUsage
-
Running the Application: Execute
Main.pyto launch the application. This script uses the cleaned data fromdiamonds.csvand a pre-trained Random Forest Regressor model to predict diamond prices. -
Interacting with the GUI:
- The GUI allows you to visualize data and predict diamond prices. It consists of two Tabs:
-
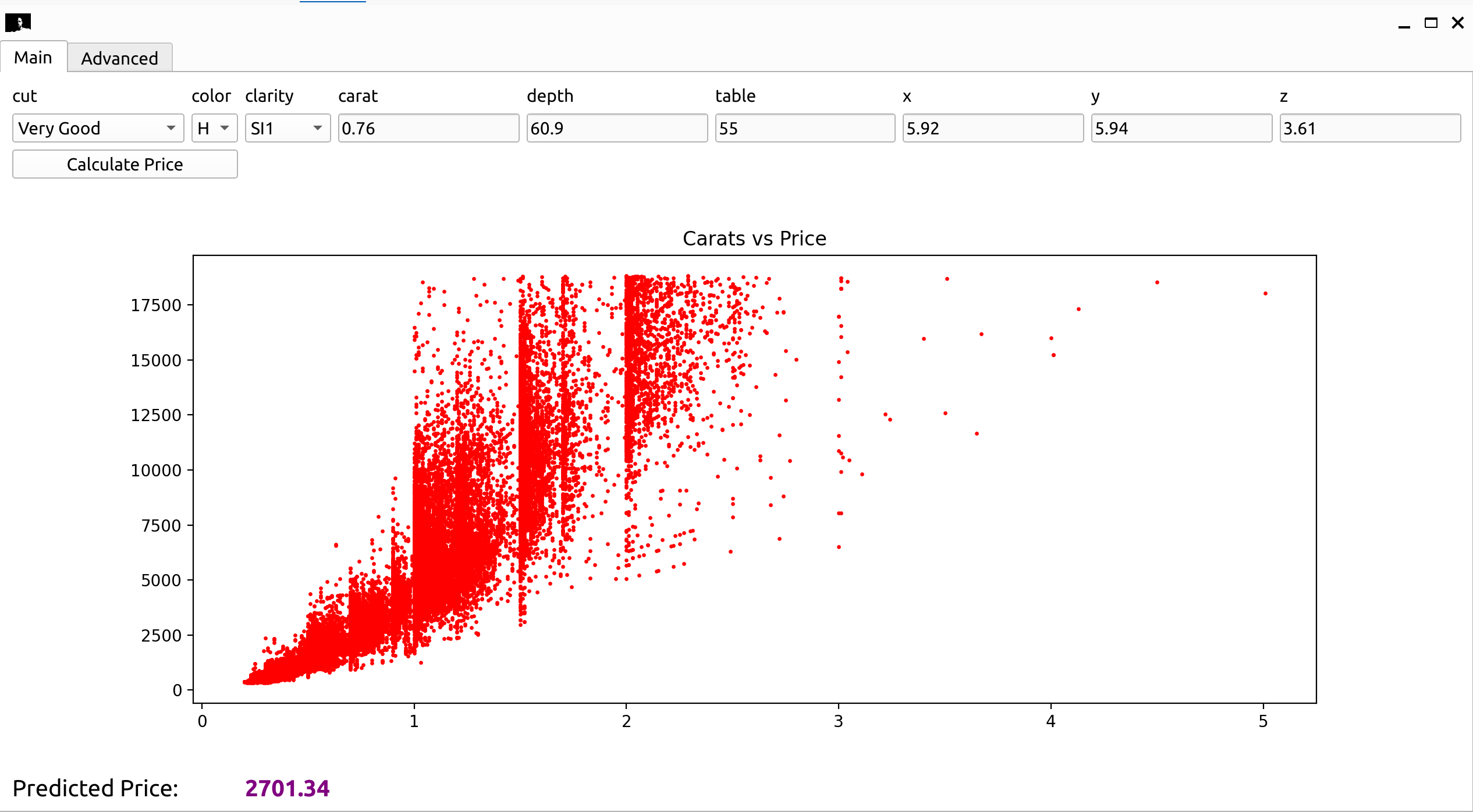
Main Tab: Enter values for the diamond attributes and click on the
Calculate Pricebutton to predict the price of the diamond. The predicted price will be displayed in thePredicted Pricefield at the bottom. In addition, the main window displays a scatter plot of the carat weight vs. the price of the diamonds in the dataset.
-
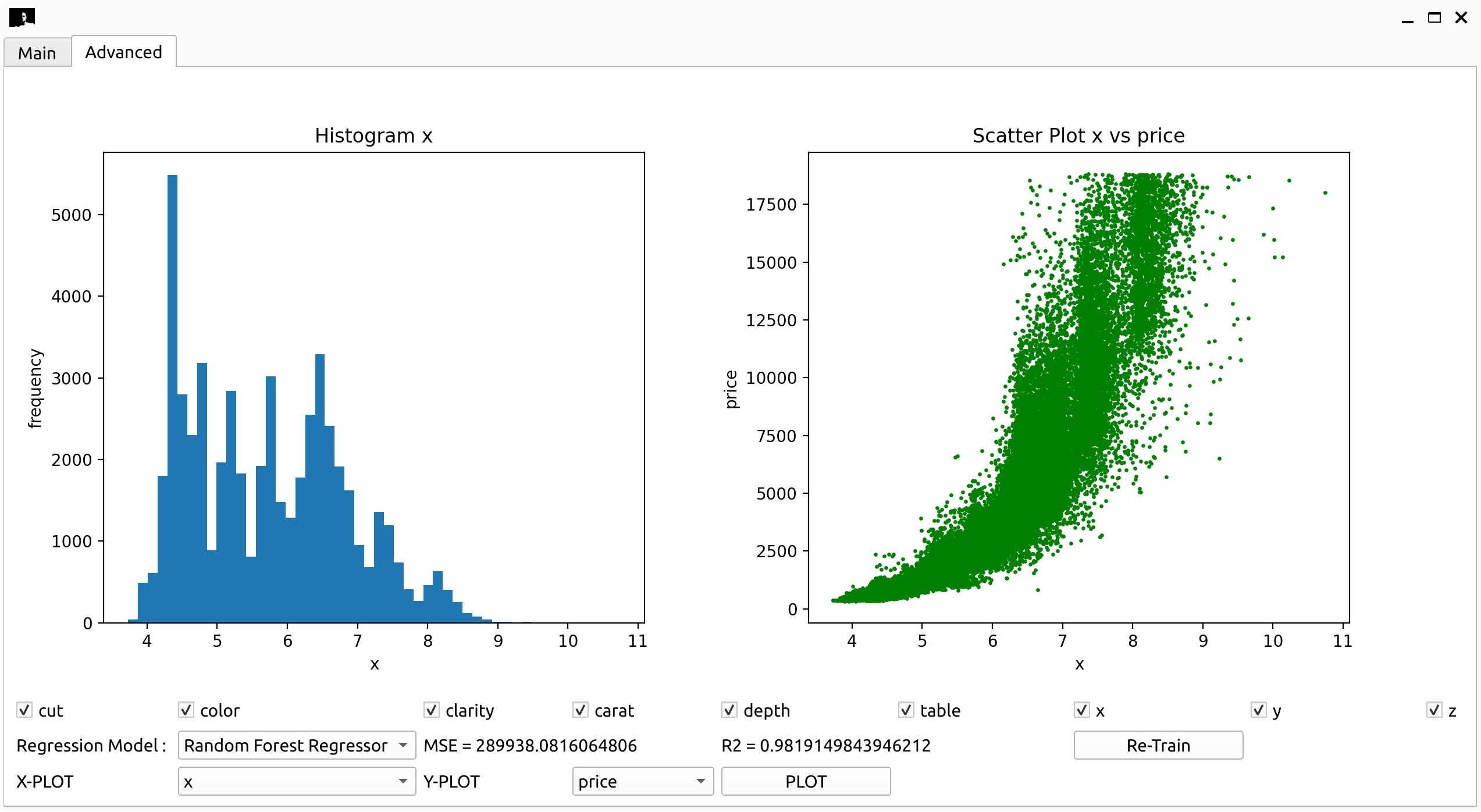
Advanced Tab: This tab allows you to visualize the relationship between the price and the other attributes of the diamonds. Select an attribute from the dropdown menu and click on the
Plotbutton to display the scatter plot. Also you can select the model you want to use for prediction from the dropdown menu and choose which attributes you want to use for prediction. The unselected attributes's fields will be disabled in the main tab. The Calculate Pricebutton will be disabled until the model is re-trained.
Model Selection
The following models are available for prediction:
-
Linear Regression: This model assumes a linear relationship between the dependent and independent variables. We used the
LinearRegressionclass from scikit-learn to train this model. The model achieved an R2 score of 0.88 and a mean squared error of 1,896,296.20 -
XGBoost Regressor: This model is an ensemble of decision trees. We used the
XGBRegressorclass from scikit-learn to train this model. The model achieved an R2 score of 0.98 and a mean squared error of 303,969.39 -
Multi-layer Perceptron Regressor: This model is a feedforward neural network with multiple hidden layers. We used the
MLPRegressorclass from scikit-learn to train this model. The model achieved an R2 score of 0.91 and a mean squared error of 31,366,191.38 and takes the longest time to train. -
Random Forest Regressor: This model is an ensemble of decision trees. We used the
RandomForestRegressorclass from scikit-learn to train this model. The model achieved an R2 score of 0.98 and a mean squared error of 292,726.76 Making it the best model for this dataset.
| Model | R2 Score | Mean Squared Error |
|---|---|---|
| Linear Regression | 0.88 | 1,896,296.20 |
| XGBoost Regressor | 0.98 | 303,969.39 |
| Multi-layer Perceptron Regressor | 0.91 | 31,366,191.38 |
| Random Forest Regressor | 0.98 | 292,726.76 |
Project Structure
-
diamonds.csv: Dataset containing diamond attributes. -
Main.py: Main Python script with GUI for prediction and visualization. -
requirements.txt: List of Python packages required for the project. -
training.ipynb: Jupyter notebook for data preprocessing and analysis. -
src/: Folder containing images used in this README. -
models/: Folder containing the trained models.